
Bank Account Fraud Detection

For a more detailed analysis, check out the full repo on Github. You can even copy the notebook and run the code yourself.
Project Goal
The goal of this project is to accurately and responsibly predict fraudulent bank account applications. This will be done by setting a maximum accepted FPR (false positive rate) and optimizing the TPR (true positive rate) within those confines. Additionally, fairness metrics will be used to ensure that the models are not biased against certain protected classes of people.
Stakeholder
The stakeholder is the Office of the Comptroller of the Currency (OCC), an independent bureau of the US Department of the Treasury. The OCC is responsible for regulating and supervising all national banks. This project is aimed to assist them in establishing industry standards to ensure banks can effectively identify fraud while protecting consumer interests.
Data
The dataset comes from a research study about the creation and use of tabular datasets for machine learning evaluation. The dataset, study, and explanatory information can be found at the following locations:
Dataset attributes:
- 1 million observations
- 30 features
- anonymized protected features
Methods and Metrics
Because the dataset is extremely imbalanced, accuracy is not a suitable metric. A model that always predicts ‘not fraudulent’ would have an accuracy score of around 98.9% despite not identifying a single instance of fraud. Therefore, I will be using alternate metrics to evaluate the models. I will use the ROC (Receiver Operating Characteristic) curve to judge the models. With the ROC curve, I will calculate the AUC (area-under-curve), along with the TPR (true positive rate) of the model at a set FPR (false positive rate) threshold.
- AUC: gives an overall score of how well the model performs at each threshold. Scores range from 0-1 with 1 being a perfect model.
- TPR at a set FPR: this will give the TPR, also known as Recall, at a set level of FPR. For the purposes of this analysis, I will use a set FPR of 0.05 (5%). This means that the models will be judged on how well they can identify the true positive instances of fraud while allowing that the model will predict false positives 5% of the time.
The models will be trained on a training set using cross validation. From there, the models will be tuned until a “best” model is found. The best models will then be evaluated on the test set. Finally, a fairness and bias analysis will be performed on each model.
Fairness and Bias Metrics
In order to evaluate fairness and bias, I will be using the Aequitas Bias and Fairness Audit toolkit to determine if the models are biased against certain groups within the protected classes. Primarily, I will be looking at the FPR of each sub-group to determine if the applications of certain subgroups are being falsely identified as fraudulent at a disproportionate rate.
Modeling
Since this is a classification task, I began with a relatively simple logistic regression model as my baseline to compare against future models. In total, I built the following models:
- Logistic Regression
- KNN
- Random Forest
- Gradient Boosting
- Voting Classifier
After building initial versions of each model, I iteratively improved upon them by tuning hyperparameters when appropriate.
Model Evaluation
The KNN model underperformed compared to the rest. Of the others, the voting classifier slightly outperformed the next best model: gradient boosting. Below is a summary of the metrics, along with the voting classifier ROC curve:
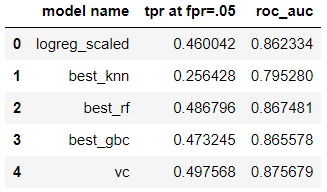
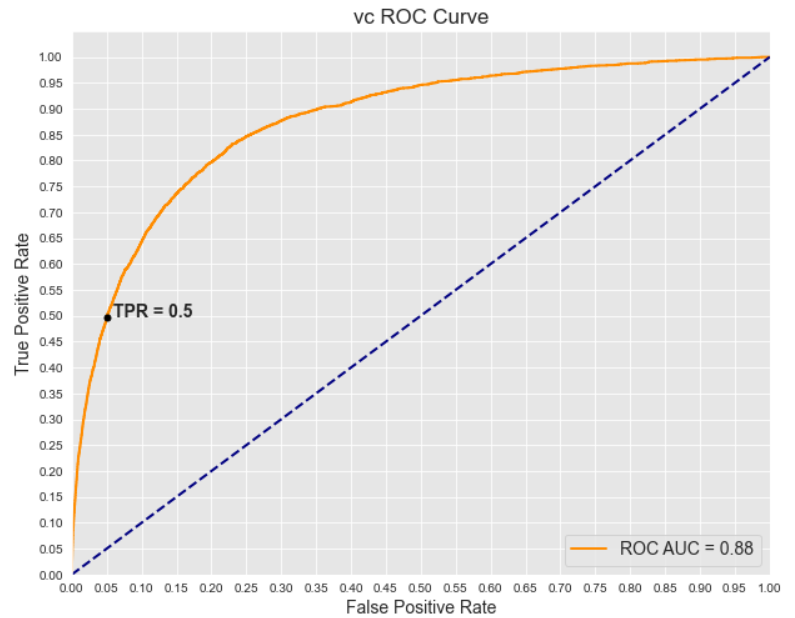
At a threshold of .05 FPR (false positive rate), the voting classifier model was able to correctly identify about half of the true positives. Now that we have several models, I can analyze them for fairness and bias.
Bias and Fairness Metrics
To evaluate bias and fairness, I used the Aequitas Fairness and Bias Audit Toolkit, a python package designed to evaluate models and data for bias. This toolkit evaluates a variety of metrics (including FPR, the main focus of this project), and compares the metrics between sub-groups. For this dataset, the “protected” categories are income, employment, and age. So these three categories were analyzed to see if certain sub-groups were being flagged as false positives at an excessive rate.
With the exception of the KNN model (which was also an outlier in terms of performance), the other models all had similar FPR distributions. Below is the distribution for the voting classifier:
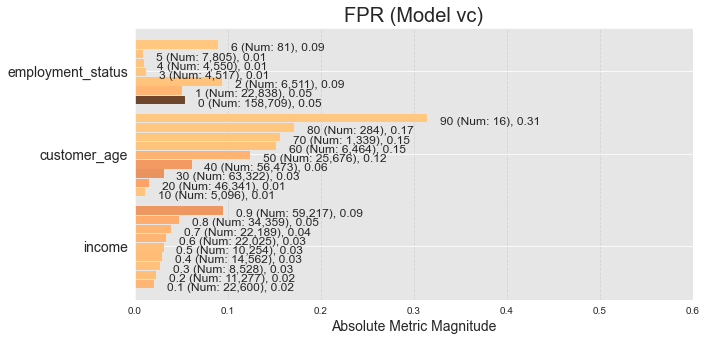
There is some bias in each group, but especially in age. This is probably in part due to the small sample size of the over 90 sub-category, but the trend continues throughout the dataset: older age increases the chance of receiving a false positive.
It is also important to note how the subgroup selection affects the results. I will create new subgroups by binning the age group into over_50 and under_50. Likewise, I will split the income group into high and low income, and see how the FPR changes for the voting classifier:
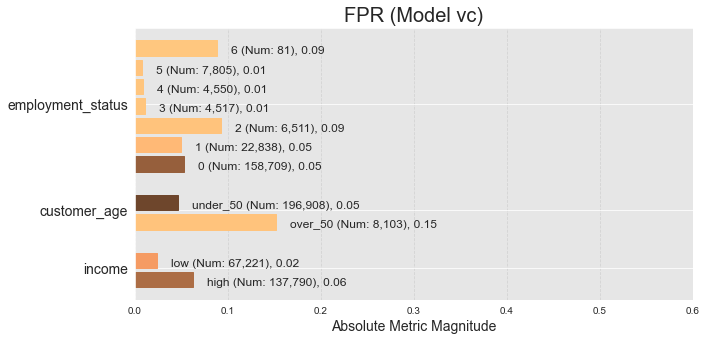
As seen above, this small change can greatly affect the ratios. However, it is important to note that the models were not trained using these categories. Ideally, the models should be re-trained using the new categories to see how performance and bias is affected.
Conclusion
After a thorough investigation of bank application fraud detection, here are a few things that stand out:
- I was unable to build a model that would prove satisfactory for the banks, as the model performance was lacking.
- the models did show signs of bias, particularly regarding the age category.
- the best performing models did share similarities in their bias/fairness metrics. Other modeling techniques should be investigated to test the impact of model selection in more detail.
Ultimately, the results are inconclusive. The models will need to perform better in order for the banks to consider using them, while the fairness and bias of the models continues to be an issue. However, hopefully this analysis will prove useful for others attempting a similar task.